
Applications
In the ADMIRE project, the dynamic allocation of resources to jobs is crucial. This is particularly true for applications that involve training Deep Learning (DL) models on large datasets. DL has unleashed advances in applications from various disciplines, such as physics or medicine, reaching unprecedented performances compared to traditional Machine Learning.
Remote sensing
One such application involves training a DL model on a large remote sensing (RS) dataset called BigEarthNet, with the goal of land cover classification. Given the size of the dataset and the deep DL model involved, many resources are required for training and inference.

Fig I. RGB images acquired by the Sentinel-2 satellite mission.
Life sciences
Another application utilizing DL models is the Life-Sciences Application trained on sequences of mice cerebellum microscope images. The goal is to detect the early stages of polyglutamine diseases. Given that every mouse cerebellum consists of hundreds of sequences of high-resolution images, DL needs to be involved in processing such a vast amount of imaging data.
Distributed deep learning
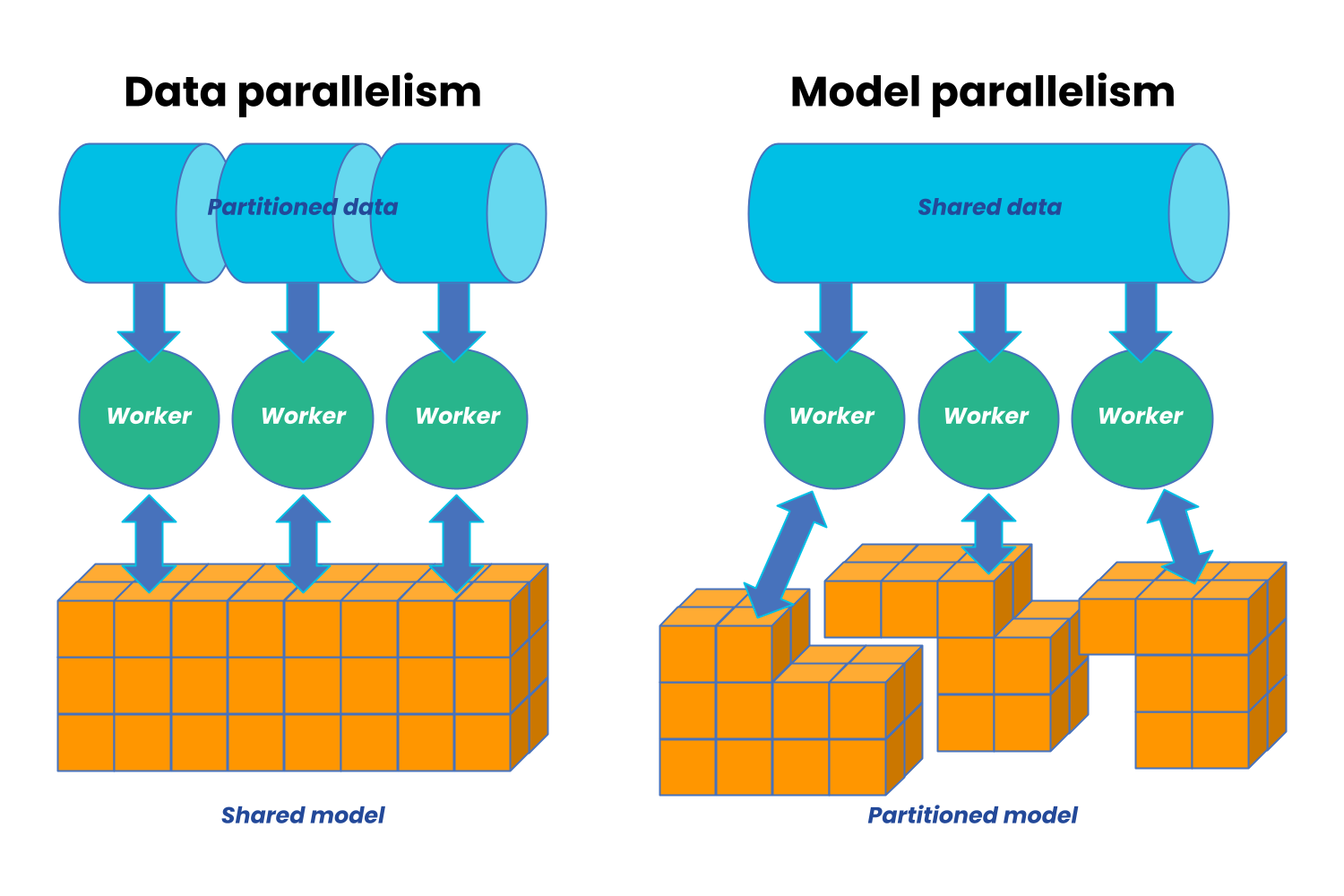
This is where Distributed Deep Learning (DDL) comes into play, as it can significantly speed up the process and reduce the time needed for classification. However, running DL applications in a dynamic environment can be challenging. There are two prominent families of approaches to scale models on multiple workers in a parallel fashion: data parallelism and model parallelism. While the data is chunked in the former, and a subset is fed into a replica of the DL model on each device, the latter splits the DL model among workers.
Elastic Horovod
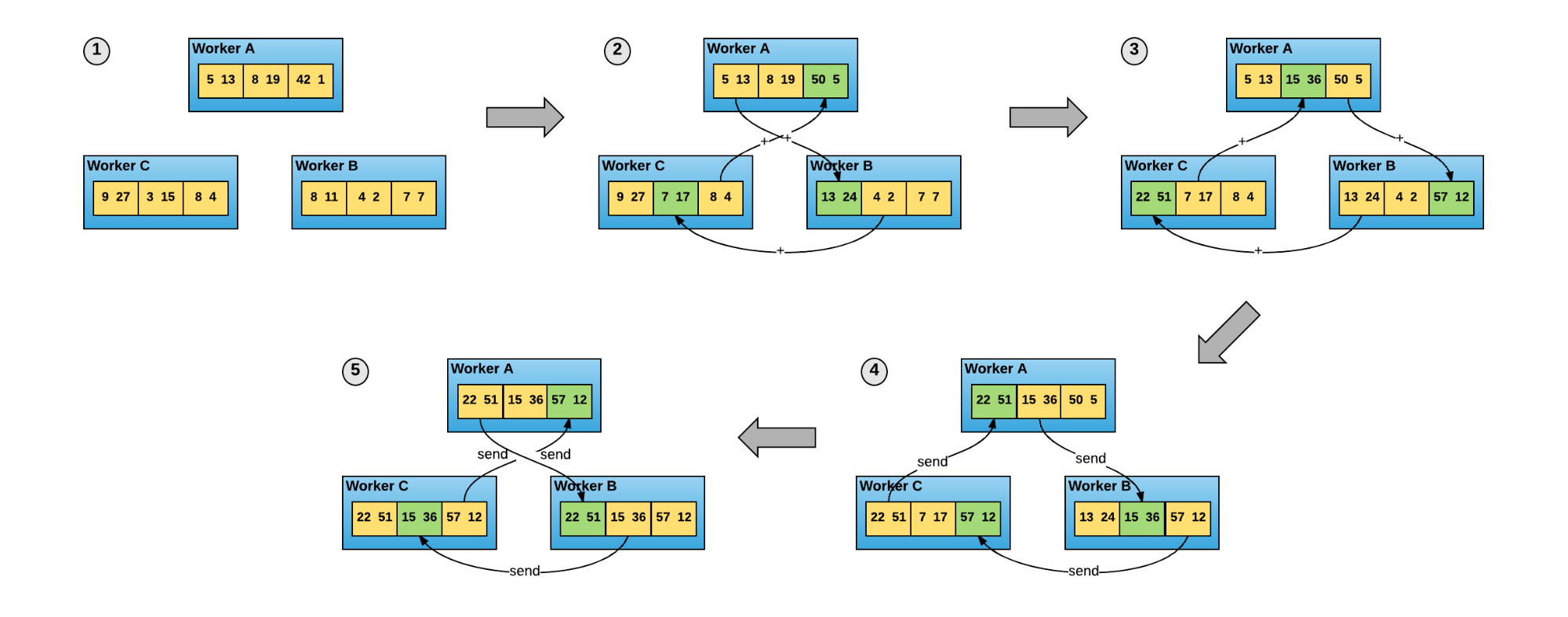
Horovod is a framework for data parallelism that can work on top of existing DL libraries. It adopts an efficient distributed algorithm to exchange the local gradients among the workers, aggregates them into global gradients, and updates the weights of the DL model. The ADMIRE project plans to adopt Elastic Horovod to address this challenge. This software allows workers at runtime without requiring a restart or resuming from checkpoints saved to join or leave the Horovod job without interrupting the training process.
What’s next…
By adopting Elastic training for Horovod, the ADMIRE project has found a means to provide the two DL applications with a strategy to respond to the dynamic requirements of the project. In this way, the applications can be continually scaled up or down depending on the needed resources, ensuring efficient resource utilization and optimal performance.
44 thoughts on “Deep Learning and Dynamic Ressources”
Comments are closed.